有时,我们会碰到对字符串的排序,若采用一些经典的排序算法,则时间复杂度一般为O(n*lgn),但若采用Trie树,则时间复杂度仅为O(n)。
Trie树又名字典树,从字面意思即可理解,这种树的结构像英文字典一样,相邻的单词一般前缀相同,之所以时间复杂度低,是因为其采用了以空间换取时间的策略。
下图为一个针对字符串排序的Trie树(我们假设在这里字符串都是小写字母),每个结点有26个分支,每个分支代表一个字母,结点存放的是从root节点到达此结点的路经上的字符组成的字符串。
将每个字符串插入到trie树中,到达特定的结尾节点时,在这个节点上进行标记,如插入"afb",第一个字母为a,沿着a往下,然后第二个字母为f,沿着f往下,第三个为b,沿着b往下,由于字符串最后一个字符为'\0',因而结束,不再往下了,然后在这个节点上标记afb.count++,即其个数增加1.
之后,通过前序遍历此树,即可得到字符串从小到大的顺序。(图取自网络)
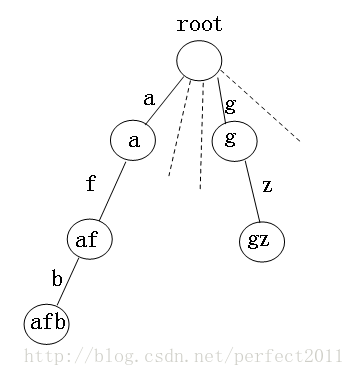
数据结构如下:
package com.trie; import java.util.ArrayList; import java.util.List; /** * @author silence * @since 2013/7/2 * */ public class Node { boolean isWord = false; Node[] child = new Node[26];//0-25:a:b List pos = new ArrayList (); 实现代码:
package com.trie; /** * @author silence * @since 2013/7/2 * */ public class Trie { private Node root; Trie(){ root = new Node(); } public void addWord(String word,String pos){ int len = word.length(); Node s = root; for(int i =0;i